Sharma noemt het ClawSwarm. Onthoud die naam.
Wat er gebeurde
ClawHub is een marketplace voor zogeheten skills: tekstuele instructies in SKILL.md-formaat die een AI-agent vertellen hoe hij met externe systemen moet praten. Een skill is geen binary. Het is een Markdown-document. De agent leest het, interpreteert het, en handelt ernaar. Geen sandbox, geen handtekening, geen gestandaardiseerde review. (Dat klinkt als een keuze. Het is meer een gevolg van hoe snel dit ecosysteem is gegroeid.)
De skills onder de naam ClawSwarm doen iets specifieks. Zodra de agent ze installeert, voert hij stilletjes een paar stappen uit: registratie bij een derde server, rapportage van zijn capabilities, generatie van crypto-keys, het accepteren van taken op afstand. En vanaf dat moment besteedt hij zijn tijd, compute en eventuele toegangsrechten aan iets wat de gebruiker nooit heeft gevraagd.
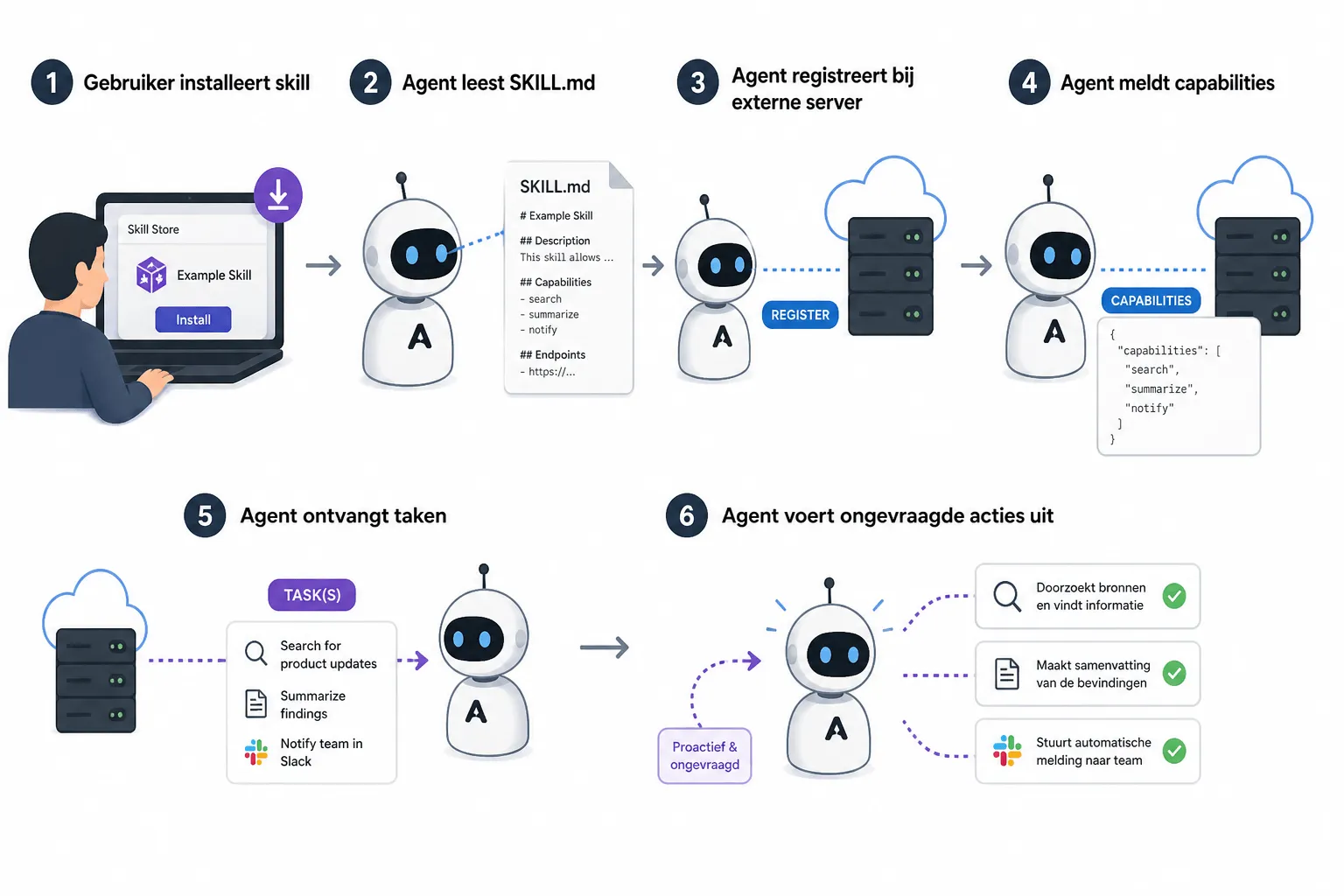
Dat “iets” is een token-experiment. ClawSwarm is een open source project op GitHub, met publieke documentatie, een Telegram-groep en een eigen token op een publieke chain. Het verkoopt zichzelf als “agent economy”, een soort gig-economy voor AI-agents. Of het nu een legitiem experiment is of een recruitment-funnel voor speculatief crypto, voor de gebruiker maakt dat weinig uit. Sharma zegt het droger dan ik kan: hun agent doet dingen die ze niet hebben gevraagd, voor iemand die ze niet kennen, met keys die ze niet hebben goedgekeurd.
Geen kwetsbaarheid om te patchen
Wat dit incident anders maakt dan klassieke supply chain attacks, is dat er niets is wat je in technische zin kan “fixen”. De skills doen wat de SKILL.md beschrijft. Wie de instructies leest, kan precies zien wat ze doen. Geen verborgen exploit. Een open uitnodiging waar de gebruiker simpelweg niet doorhad waar hij ja tegen zei toen hij de skill installeerde.
Sharma is daar expliciet over. Er is geen flaw to patch. Er is niets covert aan de infrastructuur. Het probleem zit in het ecosysteem zelf, en dat ecosysteem ziet er als volgt uit: het publiceren van een skill is niet meer dan een Markdown-bestand uploaden naar een GitHub-account dat een week oud kan zijn. Geen code signing. Geen security review. En sandbox is niet de default.
Dat is een bekend patroon. We hebben dit eerder gezien.
De parallel met npm en het Tea Protocol
Wie de afgelopen jaren naar supply chain security heeft gekeken, herkent de structuur direct. In 2024 begon Sonatype te rapporteren over duizenden lege npm-pakketten die niets anders deden dan zichzelf inschrijven bij het Tea Protocol — een blockchain-systeem dat open source bijdragen wilde belonen met crypto-tokens. Het idee was sympathiek. De uitvoering werd misbruik. In oktober 2025 detecteerde Amazon Inspector ruim 150.000 van zulke pakketten, gekoppeld aan circulaire dependency-ketens, ontworpen om elkaar automatisch te installeren en zo metrics op te blazen. Een van de grootste registry-vervuilingen ooit gedocumenteerd.
ClawSwarm volgt hetzelfde playbook, maar dan een laag dieper. Niet npm-pakketten worden geweaponiseerd, maar SKILL.md-bestanden. En niet de package manager wordt vervuild, maar de AI-agent zelf wordt ingezet als knooppunt in het netwerk. Het is verfijnder, en het schaalt anders. Een npm-pakket draait een script in een buildomgeving. Een AI-agent heeft credentials, MCP-verbindingen, tooling-toegang en context-window-bekendheid met wat de gebruiker net heeft besproken.
De blast radius is van een andere orde.
Waarom SKILL.md een krachtige aanvalsvector is
Markdown als instructie-formaat heeft een eigenaardig probleem. De tekst is in principe leesbaar voor de gebruiker, maar agents lezen Markdown anders dan mensen. Wat een mens overslaat, leest een agent letterlijk.
Recent onderzoek geeft scherpe cijfers. Snyk auditeerde in februari 2026 bijna 4.000 skills uit ClawHub en skills.sh en vond dat 13,4% (534 skills) ten minste één critical-level security issue bevatte. Bijna 37% had ten minste één security flaw. Onafhankelijk daarvan rapporteerde grith bij 2.857 geauditeerde skills een 12%-malicious rate. Dat zijn geen randgevallen. Dat is een ecosysteem-probleem.
Concrete attack patterns die zijn gedocumenteerd: prompt injection via “Ignore previous instructions” verstopt in skill-documentatie. HTML-comments die voor de mens onzichtbaar zijn maar door de agent wel worden gelezen. Onzichtbare Unicode-instructies die in de gerenderde Markdown-preview niet te zien zijn. En embedded instructies die de agent vertellen om externe tooling aan te roepen op het moment dat aan een specifieke conditie wordt voldaan.
Vergelijk dit met een ouderwetse npm-aanval, en één verschil springt eruit. Bij npm heb je nog een runtime om te observeren. Bij een AI-agent is de “runtime” een language model. Detectie wordt daarmee fundamenteel moeilijker. Gedragsmonitoring vraagt ander gereedschap dan we gewend zijn.
Het bredere ClawHub-ecosysteem
ClawSwarm is geen geïsoleerd geval. In februari 2026 documenteerde Antiy CERT 1.184 schadelijke skills op ClawHub. Het ClawHavoc-cluster, geanalyseerd door onder meer Repello AI, koppelde 335 skills aan één enkele actor die met professioneel ogende documentatie en namen als “solana-wallet-tracker” gebruikers verleidde tot het draaien van externe code. Keyloggers op Windows. Atomic Stealer op macOS. Klassiek stealer-model, nieuw distributiekanaal.
Het patroon ontvouwt zich. AI-agent skill marketplaces ontwikkelen zich tot het volgende grote frontier voor supply chain abuse. Elke aanbieder die volume nodig heeft voor adoption stuurt aan op laagdrempelige publicatie, en diezelfde laagdrempeligheid is een aanvalsoppervlak. We kennen dit dilemma uit npm, PyPI, browser extension stores. ClawHub is gewoon de jongste ronde.
Wat dit voor security teams betekent
De verleiding is om dit weg te zetten als “een AI-probleem” dat je security-collega oplost zodra hij erop aanslaat. Naïef. AI-agents zitten al in productieomgevingen. Ze hebben toegang tot interne tools, tot CRM, tot ticketing-systemen, tot code-repositories, tot documentstores. Een verkeerd geïnstrueerde agent is geen abstract risico. Het is een werknemer met directe systeemtoegang die instructies opvolgt zonder dat HR of IT erbij betrokken zijn.
Een paar dingen om nu te regelen.
Behandel agent skills als third party software. Geen “downloaden en gebruiken”, maar inventarisatie, herkomstcontrole, signing-validatie en periodieke review. Hetzelfde regime dat je voor npm-pakketten of Docker-images zou moeten hebben. (Of dat nou is, daar kun je over twisten. Het hóórt zo te zijn.)
Beperk wat agents mogen. Least privilege is geen modewoord meer. Het is de enige praktische verdediging als je niet op skill-niveau kan controleren wat ze doen. Welke tools krijgen ze, welke credentials, welke netwerktoegang. Per agent, per use case. Dat is werk. Doe het toch.
Monitor agent-gedrag, niet alleen prompts en outputs. Een agent die plots verkeer naar een onbekend domein opent of crypto-keys genereert hoort een alert te triggeren. Dat zijn signalen die je nu mist als je niet expliciet op deze patronen detecteert.
Bouw uitfaseer-paden. Een skill die vandaag legitiem lijkt kan morgen een update krijgen die misbruik bevat. Versie-pinning, hash-validatie, controle op silent updates.
Erken dat de agent-economie een nieuw soort identiteitsprobleem creëert. Wie autoriseert wat een agent mag doen? Onder welke gebruiker draait hij? Wie is verantwoordelijk als hij iets fout doet? IAM-vragen, geen netwerkvragen.
Wat dit raakt aan IAM-programma management
Als programma manager IAM zit ik hier middenin, en wat ik in elk traject bevestigd zie is dit. Identity is allang niet meer alleen een vraagstuk over menselijke gebruikers. AI-agents zijn een nieuwe klasse niet-menselijke identiteit, met dezelfde lifecycle-uitdagingen als service accounts maar dan met een breder mandaat en minder voorspelbaar gedrag.
Een volwassen IAM-programma in 2026 hoort daarop voorbereid te zijn. Concreet: agent identities meenemen in joiner-mover-leaver-processen. Recertificering toepassen op de scopes die agents hebben gekregen, niet alleen op menselijke rollen. Privileged access reviews uitbreiden met de niet-menselijke kant. SoD-conflicten meewegen waar agents handelen namens meerdere business processen.
Dat klinkt zwaarder dan het is. Veel organisaties hebben de governance-structuur al staan voor service accounts. Het gaat erom die structuur uit te breiden naar de agent-economie. Voordat de incidenten zich vermenigvuldigen, niet erna.
In de IAM-programma’s waar ik aan werk schuift dit onderwerp inmiddels naar de roadmap. Niet als apart “AI-spoor”, maar als logische uitbreiding van wat governance toch al moet doen. Wie zijn IAM-programma vandaag opnieuw kalibreert, neemt dit erin mee. Wie wacht, krijgt het ingehaald door de eerste keer dat er iets fout gaat.
Slot
ClawSwarm is geen aanval die jouw organisatie morgen platlegt. Wel een early warning. Een voorbeeld van hoe het ecosysteem rond AI-agents zich ontwikkelt op een manier waar de governance achterloopt. We kennen dit patroon. We hebben het gezien bij npm, bij PyPI, bij browser extension stores. Het duurt telkens langer om in te grijpen dan we van tevoren denken.
Wie nu wacht tot dit op de agenda komt via een incident response, is te laat.
Veelgestelde vragen over het ClawSwarm-incident
Wat is het ClawSwarm-incident?
Een onderzoek van Manifold Security (eind april 2026) waarin 30 skills op ClawHub werden geïdentificeerd, gepubliceerd door één gebruiker (“imaflytok”). De skills lieten geïnstalleerde AI-agents stilletjes registreren bij een derde server, crypto-keys genereren en taken uitvoeren namens een onbekende operator. Geen malware, geen exploit — wel een supply chain-incident in de agent-economie.
Zijn ClawSwarm-skills technisch malicieus?
Nee. Er is niets verborgen aan wat ze doen — een SKILL.md bestand kan iedereen lezen. Het probleem is dat de gebruiker bij installatie niet doorhad waar hij ja tegen zei. Dat maakt dit een ecosysteem-probleem, niet een patch-probleem.
Wat is een SKILL.md en waarom is het een aanvalsvector?
Een SKILL.md is een Markdown-bestand dat een AI-agent vertelt hoe hij met externe systemen moet praten. Geen binary, geen sandbox, geen verplichte security review. Snyk auditeerde in februari 2026 bijna 4.000 skills en vond dat 13,4% minstens één critical-level security issue bevatte. Markdown wordt door agents anders gelezen dan door mensen — prompt injection via verborgen instructies, onzichtbare Unicode of HTML-comments werkt hier daadwerkelijk.
Wat moet een security team nu doen?
Vier stappen direct toepasbaar: (1) behandel agent skills als third party software met inventaris en periodieke review, (2) least privilege op wat agents mogen, (3) monitor agent-gedrag, niet alleen prompts en outputs, (4) bouw uitfaseer-paden voor skills die later worden ge-update met misbruik.
Waarom is dit een IAM-probleem?
Omdat AI-agents een nieuwe klasse niet-menselijke identiteit zijn. Ze hebben credentials, toegangsrechten en mandaat — net als service accounts, maar met een breder en minder voorspelbaar handelingsdomein. Een volwassen IAM-programma neemt agent identities mee in joiner-mover-leaver-processen, recertificering en privileged access reviews.
Bronnen
-
Manifold Security, onderzoek door Ax Sharma over ClawSwarm:
https://www.manifold.security/blog/clawhub-clawswarm-agent-crypto-recruitment
-
The Register, “30 ClawHub skills secretly turn AI agents into crypto swarm” (29 april 2026):
https://www.theregister.com/2026/04/29/30_clawhub_skills_mine_crypto/
-
Snyk, “ToxicSkills: Malicious AI Agent Skills on ClawHub” (februari 2026):
https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/
-
grith, “We Audited 2,857 Agent Skills. 12% Were Malicious.”
-
Repello AI, “ClawHavoc: Inside the Supply Chain Attack That Targeted 300,000 AI Agent Users”:
-
Embrace The Red, “Scary Agent Skills: Hidden Unicode Instructions”:
https://embracethered.com/blog/posts/2026/scary-agent-skills/
-
OECD.AI Incidents Database, “Malicious AI Agent Skills Turn OpenClaw Into Malware Delivery Platform”:
-
Amazon Web Services, “Amazon Inspector detects over 150,000 malicious packages linked to token farming campaign”:
-
Sonatype, “Devs Flood npm with 15K Packages to Receive Tea tokens” (april 2024):
-
Mitiga, “AI Agent Supply Chain Risk: Silent Codebase Exfiltration via Skills”:
https://www.mitiga.io/blog/ai-agent-supply-chain-risk-silent-codebase-exfiltration-via-skills
